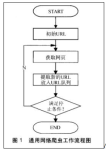
网络爬虫又名“网络蜘蛛”,是通过网页的链接地址来寻找网页,从网站某一个页面开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到按照某种策略把...
”ECommerceCrawlers web爬虫程序 web爬虫工具“ 的搜索结果

跟朋友聊天斗图失败气急败坏的我选择直接制作一个爬虫表情包小程序,从源头解决问题,从此再也不用担心在斗图中落入下风
Spider:爬虫逻辑模块,核心模块群,可根据需要添加新爬虫模板,爬虫模板可继承,基模块为Spider.py,多个相似爬虫可根据规则设置复用同一个爬虫模板 Model:数据模型模块,维护爬虫相关ORM数据模型,由上下文管理...
81个Python爬虫源代码
标签: 爬虫
81个Python爬虫源代码,内容包含新闻、视频、中介、招聘、图片资源等网站的爬虫资源
而要开发一款高效、稳定的网络爬虫,离不开一系列强大的爬虫工具。本文将为您盘点一些爬虫必备的工具,帮助您快速构建出具有实际价值的网络爬虫。让我们一起探索吧!一、请求库1.Requests:这是Python中最流行的HTTP...


webscraper爬虫工具详细操作
标签: 爬虫

1.首先给爬虫程序找到储存路径 2.按住shift和右键,选择在此处打开Powershell窗口(s) 3.在窗口内输入scrapy(杀毒软件可能会阻止程序运行,不要选择阻止!!!如果不小心选择了阻止,把杀毒软件退掉,重新从第二步...
我相信很多人跟我都有相同的经历:想在网上找点资源,却因为种种原因而...有了 Python 爬虫技巧,相信很多平时你想要的资源,它都可以帮你实现。本文我将给大家分享目前做爬虫所涉及的 Python 库,总会一款是你的最爱。

多年爬虫领域老工程师深度总结反爬虫技术原理与场景,带你快速了解并掌握反爬虫技术栈知识
文章目录太长不看0....WOS_Crawler是一个Web of Science核心集合爬虫。 支持爬取任意合法高级检索式的检索结果(题录信息) 支持爬取给定期刊列表爬取期刊上的全部文章(题录信息) 支持选择目标文献类型...


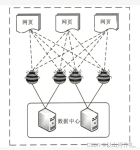
从本质上来讲,阻止Web 爬虫就意味着你需要让脚本和机器难以从你的网站上获取它们所需的数据,但不能让那些真正的用户和搜索引擎爬取数据变得困难。 然而不幸的是,要做到这一点很难,你需要在防止Web 爬虫和降级...
将工具按照以上分类说明,按照学习路线顺序给出参考文章 页面下载器 requests(必学) python爬虫入门requests模块 Python爬虫:requests库基本使用 Python爬虫:使用requests库下载大文件 Python爬虫:requests多...
python爬虫,并将数据进行可视化分析,数据可视化包含饼图、柱状图、漏斗图、词云、另附源代码和报告书。
模板爬虫的主要优势在于简化了爬虫的开发过程!降低了技术门槛,提高了爬虫的可维护性和灵活性


目前市面上我们常见的爬虫软件大致可以划分为两大类:云爬虫和采集器(特别说明:自己开发的爬虫工具和爬虫框架除外) 云爬虫就是无需下载安装软件,直接在网页上创建爬虫并在网站服务器运行,享用网站提供的带宽和...
推荐文章
- 机器学习之超参数优化 - 网格优化方法(随机网格搜索)_网格搜索参数优化-程序员宅基地
- Lumina网络进入SDN市场-程序员宅基地
- python引用传递的区别_php传值引用的区别-程序员宅基地
- 《TCP/IP详解 卷2》 笔记: 简介_tcpip详解卷二有必要看吗-程序员宅基地
- 饺子播放器Jzvd使用过程中遇到的问题汇总-程序员宅基地
- python- flask current_app详解,与 current_app._get_current_object()的区别以及异步发送邮件实例-程序员宅基地
- 堪比ps的mac修图软件 Pixelmator Pro 2.0.6中文版 支持Silicon M1_pixelmator堆栈-程序员宅基地
- 「USACO2015」 最大流 - 树上差分_usaco 差分-程序员宅基地
- Leetcode #315: 计算右侧小于当前元素的个数_找元素右边比他小的数字-程序员宅基地
- HTTP图解读书笔记(第六章 HTTP首部)响应首部字段_web响应的首部内容-程序员宅基地